Три года назад все обсуждали платье, которое разделило интернет. На днях обнаружилась похожая, ещё более интересная и сложнее объяснимая иллюзия. Какое имя вы слышите на этой аудиозаписи: «Йенни» или «Лорел»?
Как выяснилось, результаты не только различаются от человека к человеку, но даже для одного человека могут зависеть от используемого аудиооборудования. Всю неделю лингвисты спорят о причинах иллюзии, пристально разглядывая спектрограмму этого двухсекундного фрагмента. Вот она:
читать дальше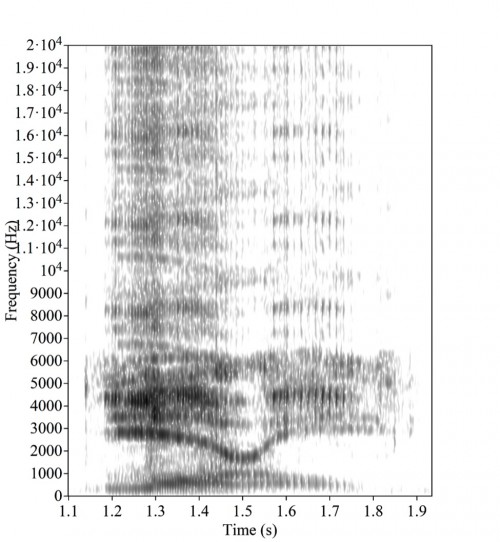
Для тех, кто видит спектрограмму звука впервые: по горизонтальной оси отложено время, по вертикальной — частоты, яркость точки соответствует амплитуде, с которой вибрирует «воображаемый камертон» соответствующей частоты в соответствующий момент времени. На спектрограмме речи всегда видны "форманты" — тёмные горизонтальные линии, извилистые и прерывистые; каждая форманта соответствует одной из резонансных частот речевого аппарата, а их вертикальные колебания — соответственно, изменениям этих резонансных частот в процессе речи.
Как объясняет Сюзи Стайлс, на участке низких частот до 5 КГц в человеческой речи присутствуют три форманты, которых обычно достаточно для разпознавания произносимых звуков. Эти три форманты соответствуют вертикальному (F1) и горизонтальному (F2) положению языка, и положению губ (F3). Сюзи даёт ссылку на ролик Общества Макса Планка, где диктор, находящийся в МРТ-камере, произносит по очереди все гласные и все согласные, так что за положением его органов речи при произношении каждого звука можно следить непосредственно.
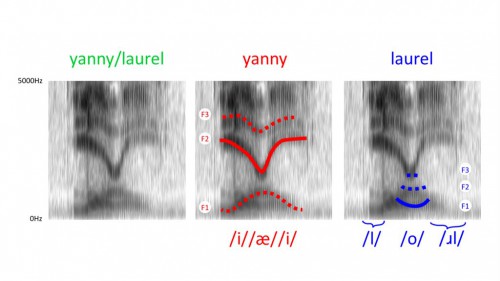
И вот с выделением формант, по словам Сюзи, возникают проблемы: тёмные участки на спектрограмме yanni/laurel образуют рисунок из более чем трёх полос, которые разветвляются и пересекаются:
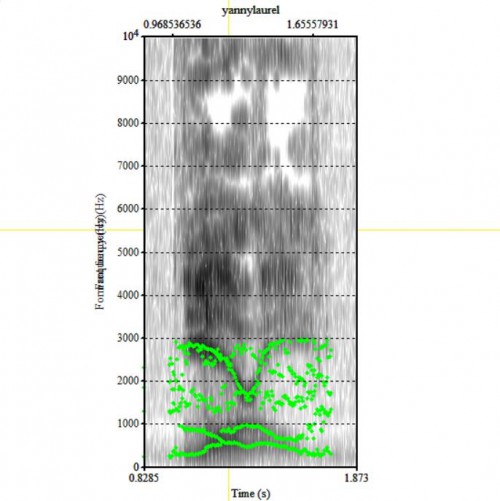
В частности, нижняя полоса (F1) может распознаться либо «горбом вверх», либо «горбом вниз»:
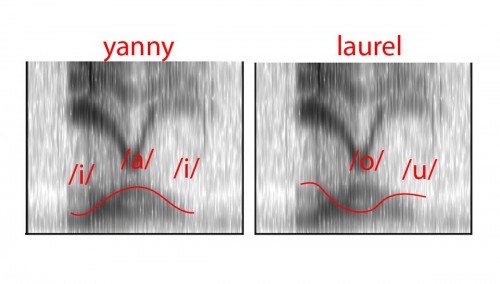
Первая линия соответствует последовательности гласных «высокий — низкий — высокий», т.е. [jæ-ɪ-]; вторая — «низкий — высокий — средний», т.е. [a-o-ə-]. (На рисунке Сюзи очевидная ошибка: [u] — высокий гласный, и не может быть в конце второй последовательности.) По F2 видно, что последовательность гласных должна быть «передний — средний — передний», т.е. опять же [jæ-ɪ-]. Но если аудиосистема слушателя подавляет частоты между 2 и 3 КГц, то слушатель «домысливает» F2 на основании F1, и получает последовательность гласных «задний-средний», т.е. [-o-ə-]:
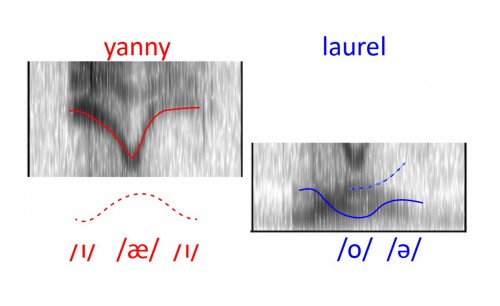
Сюзи подводит итог своего анализа: вместо трёх ясных формант мы видим путаницу из тёмных пятен, которую можно расшифровать одним из двух способов:
Немного другой анализ приводит Кэролин МакГеттиган. Когда стало известно, что «двусмысленный звук» не сконструирован коварными лингвистами для издевательства над нормальными людьми, а взят с сайта онлайн-словаря, пропущен через не очень качественные колонки, и записан не очень качественным микрофоном, — то Кэролин сравнила спектрограммы исходного звука с сайта, и получившегося «звука-иллюзии»:
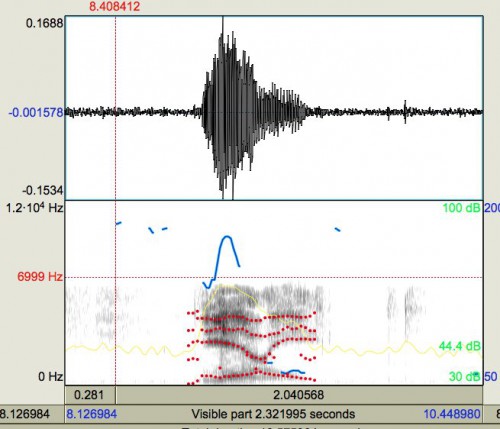
В первом звуке F1 и F2 видны чётко, но очень близки; во втором, кроме добавления слабого шума, F1 и F2 слились в одну форманту, а исходная F3 стала восприниматься как F2. Кэролин отмечает, что «горб вниз» в F3 — это отличительная черта английского звука [ɹ]; а в получившемся звуке он вместо этого стал восприниматься как «горб вниз» в F2, т.е. как последовательность гласных «передний — средний — передний» — пресловутая [jæ-ɪ-].
Кроме этих двух объяснений иллюзии, лингвисты предложили ещё несколько. Бенджамин Муссон обратил внимание, что на высоких частотах (5-9, 9-13, 13-17 КГц) содержатся более слабые повторы F1-F3:
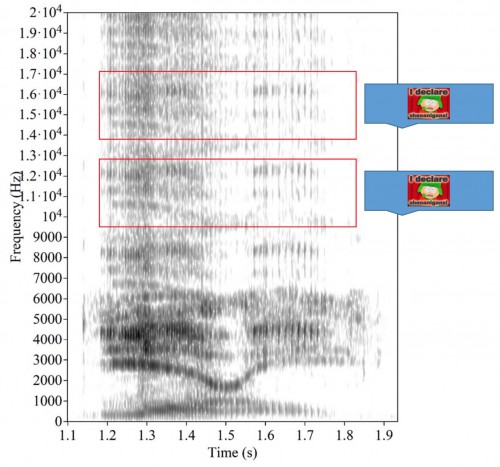
В человеческой речи таких «повторяющихся формант» не бывает, так что Бенджамин обвиняет в иллюзии именно их. (Вероятнее всего, это артефакт аудиосжатия, использованного для «двусмысленного звука».)
NY Times — обсуждение иллюзии дошло даже дотуда! — тоже обвиняет в иллюзии усиление высоких частот, произошедшее при перезаписи:
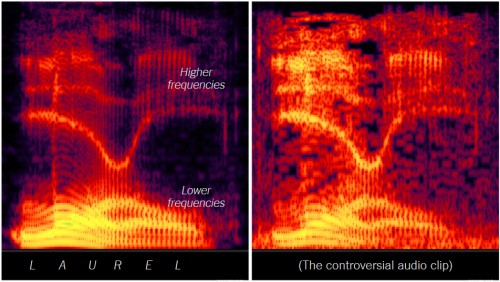
Более того, в своей заметке они реализовали «интерактивную иллюзию» — частотный фильтр, настройку которого можно плавно менять ползунком, чтобы любой мог убедиться: если усиливать низкие частоты и подавлять высокие — то звук превращается в Laurel, если наоборот — то в Yanny.
(c)
-
-
18.05.2018 в 11:18-
-
18.05.2018 в 11:22-
-
18.05.2018 в 11:28Meliana_St., а что?
-
-
18.05.2018 в 11:39-
-
18.05.2018 в 11:50Мне упорно слышится "евэй"
-
-
18.05.2018 в 12:38-
-
18.05.2018 в 12:41-
-
18.05.2018 в 12:54Ну у меня музыкальный слух и 15 лет в музыке))
-
-
18.05.2018 в 12:58-
-
18.05.2018 в 13:43-
-
18.05.2018 в 13:47-
-
18.05.2018 в 14:02-
-
18.05.2018 в 14:11Возможно, у меня эти мелконаушники как раз высокие частоты плохо передают - и потому тот дополнительный мусор, который усиливает иллюзию "йенни" по упоминавшимся в топике теориям, у меня просто не слышен и не мешает.
-
-
18.05.2018 в 14:21в том числе и на очень неплохих наушниках
-
-
18.05.2018 в 14:27-
-
18.05.2018 в 16:12А вот леттеринг-версия
-
-
18.05.2018 в 16:18-
-
18.05.2018 в 17:03-
-
18.05.2018 в 18:39-
-
18.05.2018 в 21:41Имхо, эта иллюзия не сложнее предыдущей и объясняется в целом точно так же. Поскольку это действительно "аудиоверсия платья". Там фишка была в зрительной инверсии, а здесь - в звуковой. У меня, кстати, платье получалось увидеть и так, и эдак, только глаза приходилось напрягать. Сейчас я сделала проще. Сначала услышала четкое "Лорел", а потом тупо перевернула наушники, засунув левый в правое ухо. И - бинго! Столь же четкое "Йенни". )))
-
-
18.05.2018 в 22:51-
-
18.05.2018 в 22:54-
-
19.05.2018 в 17:34-
-
19.05.2018 в 19:26-
-
20.05.2018 в 19:39